The Value Framework in Perceptive agents

Part 2 of the Pedestal AI Knowledge Series
Abstract
In Part 1 we described five common challenges in enterprise AI deployments—reliability, accuracy, performance, cost and "validate"ability—and argued they share a single architectural origin: knowledge is disparate and intertwined with instructions and context, leading to attention dilution. In this second installment we examine four approaches enterprises commonly try to close the gap: long‑context prompts, LoRA‑based fine‑tuning, prompt caching and retrieval‑augmented generation. Each yields real improvements but none reach the bar enterprise deployments require. We then introduce an architectural complement: externalizing knowledge into a persistent value framework that sits alongside the model and supplies the perception it cannot provide on its own. Our experience across industries suggests that value frameworks enable the reliable adoption of AI agents.
1. What the model knows, and what it doesn't
Modern production language models are almost invariably decoder‑only transformers. Input tokens pass through a stack of blocks containing multi‑head attention, feed‑forward networks and residual connections, with layer normalization before each sublayer, into a final softmax that produces a distribution over the vocabulary for the next token. The central operation is attention: Attention(Q, K, V) = softmax(QKᵀ/√d_k)·V, where Q, K and V are learned projections of the input sequence [1].
When a model answers a question correctly it is because the requisite knowledge was present—often redundantly—across the training corpus and has been compressed into the weights during pre‑training. This breakthrough enables remarkable competence in language, mathematics and common sense, but it also marks an architectural ceiling for enterprise use: the knowledge embedded in the weights is whatever the training data contained, it is static after pre‑training, diffused across billions of parameters and cannot be queried, audited or selectively updated. A company’s current fiscal calendar, custom margin definitions or region schemas were not in the pre‑training corpus and cannot be added without retraining or adaptation.
Figure 1. Inside a decoder‑only transformer. Input tokens flow through N transformer blocks—multi‑head attention, feed‑forward network, residual connections and layer normalization—into a final softmax over the vocabulary. Knowledge is distributed diffusely across the network’s weights; the output is a probability distribution. Adapter methods such as LoRA add small trainable components alongside the frozen base, but they do not change the opacity of the underlying weights.
2. Four common approaches, and where each reaches its ceiling
2.1 Approach 1 — long‑context prompts
The most common first response to the enterprise knowledge gap is to place missing knowledge in the prompt. If the model does not know a business term, include the definition; if it does not know the fiscal calendar, embed that too. Expanding context windows—from early 2K‑token limits to today’s 128K‑ and million‑token prompts—makes this feasible. However, the model must still attend to the portion of the prompt that matters.
Empirical work by Liu et al. [2] shows that language model accuracy declines when relevant information appears in the middle of a long context—the “Lost in the Middle” effect. Attention mass is bounded by the softmax and a critical token must compete with every other token in a long sequence. Self‑attention is also quadratic in sequence length [4], so prefill latency grows roughly with the square of context length even with optimized kernels. In real deployments, teams find that packing tens of thousands of tokens into prompts yields diminishing accuracy and significant compute cost.
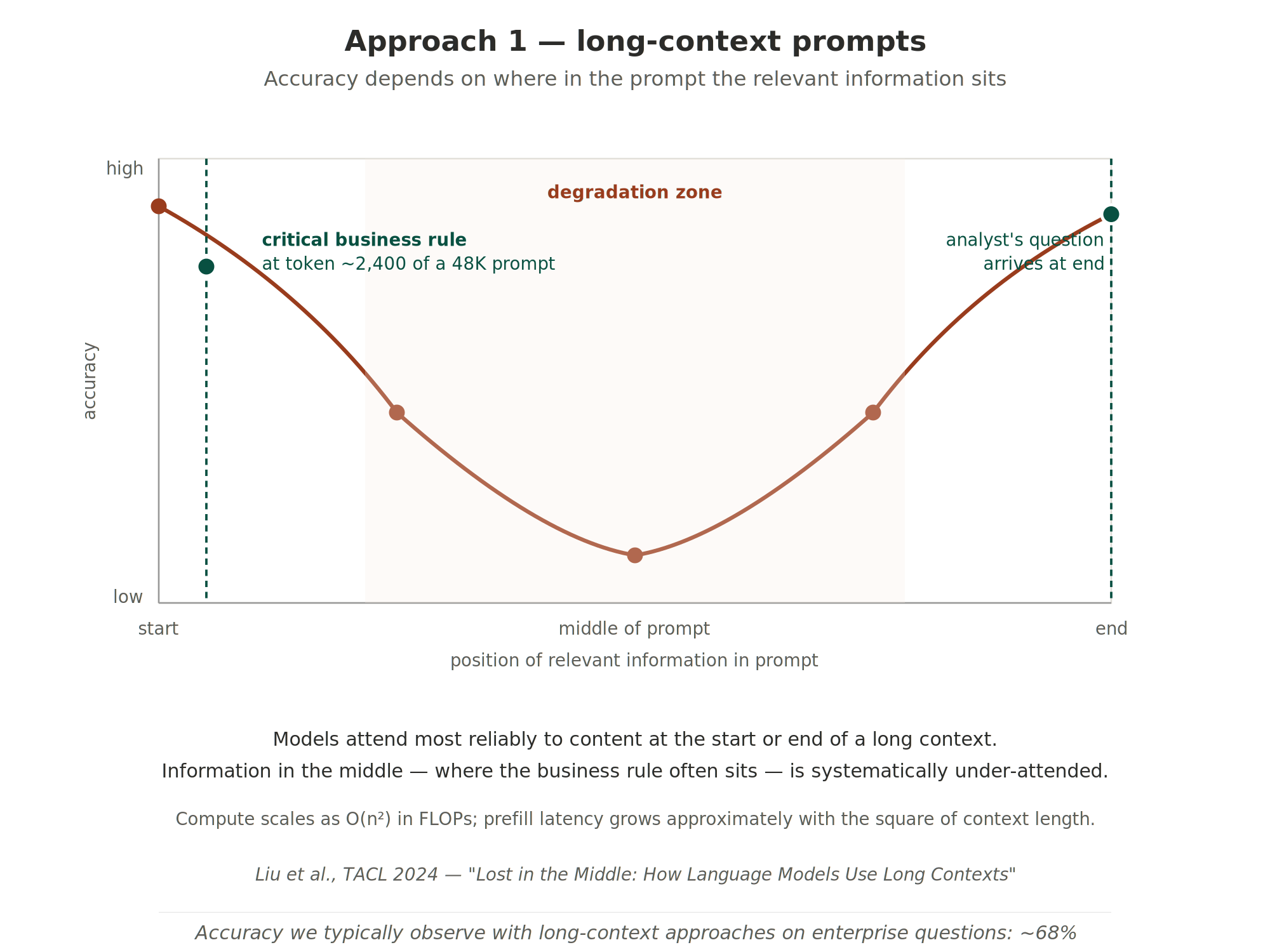
Figure 2. Approach 1—long‑context prompts. Accuracy depends on where in the prompt the relevant information sits: models attend reliably to content at the start or end of a long context, while information in the middle is systematically under‑attended. Compute scales quadratically with context length; prefill latency grows accordingly.
2.2 Approach 2 — LoRA‑based fine‑tuning
A second remedy adapts the base model via parameter‑efficient fine‑tuning. LoRA, introduced by Hu et al. [3], adds a low‑rank update alongside the frozen weights: W′ = W + B·A with rank r ≪ d. This reduces trainable parameters by orders of magnitude—by a factor of 10 000 for GPT‑3 175B—while preserving most of the adaptation quality of full fine‑tuning.
LoRA falls short for enterprise knowledge not because of capacity but because of cadence and opacity. Every change in the business—such as redefining a region or adding a margin line item—requires a new fine‑tuning cycle. Once trained, the adapted weights are not auditable: there is no trace linking a particular example to a particular answer, nor a way to selectively update a single business rule without retraining. Teams discover that the business moves faster than the adapters and that the knowledge encoded within is invisible to auditors.
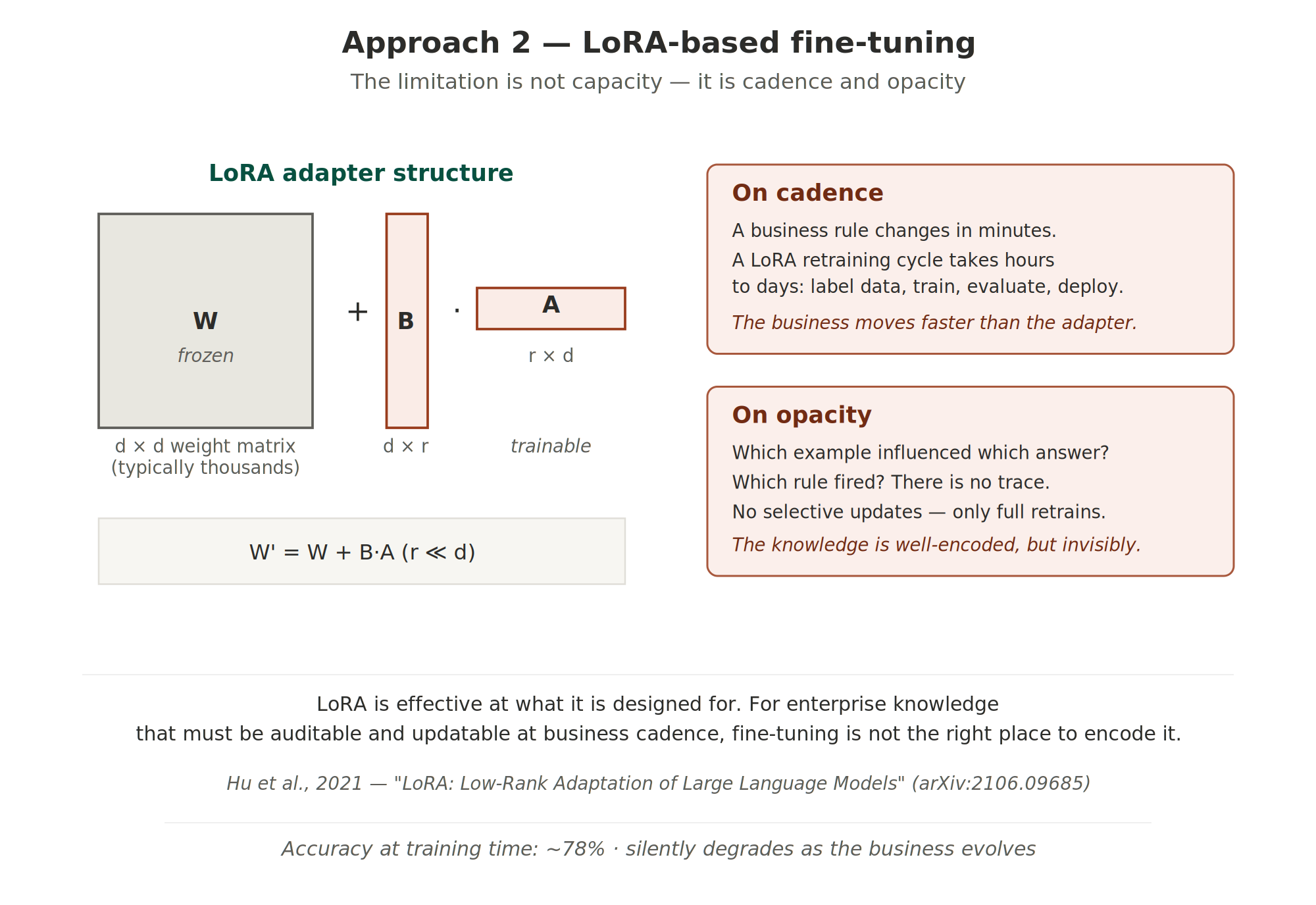
Figure 3. Approach 2—LoRA‑based fine‑tuning. LoRA adds a small trainable low‑rank component alongside the frozen base. The limitation for enterprise knowledge is not capacity but cadence and opacity: business rules change faster than adapters can be retrained, and the adapted weights provide no defensible audit trail.
2.3 Approach 3 — prompt caching
Prompt caching addresses the compute cost of long contexts rather than the knowledge gap itself. Providers such as OpenAI and Anthropic offer caches that precompute and store the key and value tensors for stable prefixes, reusing them when a prompt begins with an identical prefix [7]. Anthropic's own guidance encourages this pattern: knowledge bases under 200,000 tokens can be included wholesale in the prompt, with caching making the approach "significantly faster and more cost-effective" [9]. In multi-turn conversations, caching amortizes that cost across turns — the knowledge stays present without recomputation.
However, caching changes where compute happens, not what signal reaches the output. The model's attention at generation time still operates over the full sequence length — every cached token remains in the attention window. Recent research shows that context length alone degrades performance regardless of where evidence is positioned [8]. Caches also have no notion of semantic invalidation: when a business rule changes, a cached prompt serves stale knowledge until explicitly flushed. These are boundaries, not failures — caching was never designed to solve them. It makes large knowledge payloads economical to sustain; it does not make the model reason over them more reliably, nor guarantee the knowledge is current or governed. Accuracy we observe with knowledge stuffed in prompts with caching enabled remains in the low 70s.
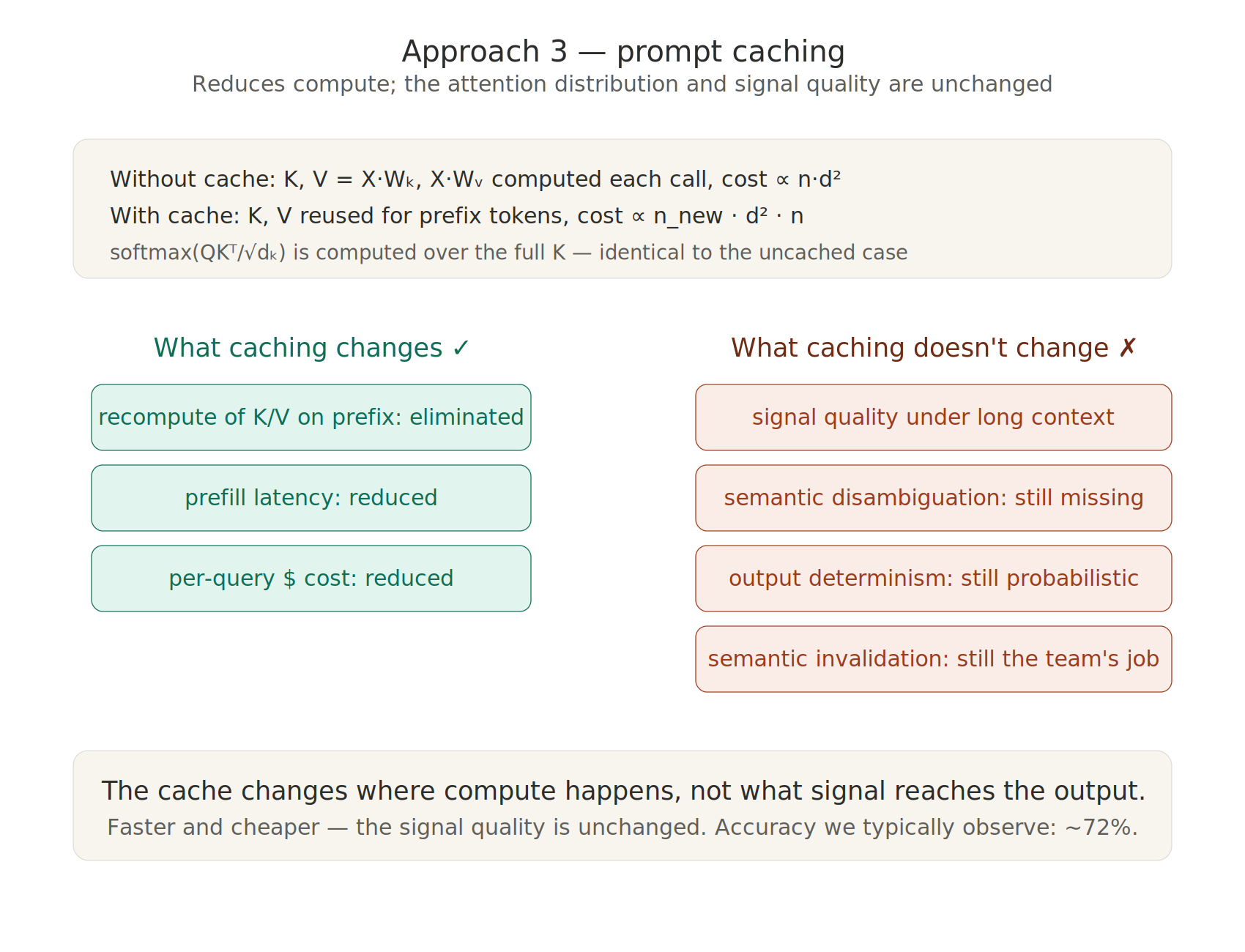
Figure 4. Approach 3—prompt caching. Provider‑managed caches reuse precomputed key/value tensors from stable prefixes, reducing compute for new queries. The attention distribution and signal quality remain unchanged; caching reduces cost and latency but does not solve semantic disambiguation, determinism or invalidation.
2.4 Approach 4 — retrieval‑augmented generation
Retrieval‑augmented generation (RAG) indexes a company’s documentation, retrieves the chunks most relevant to a query and places them in the prompt. Documents are split into chunks and embedded into a vector space; at query time the query is embedded and the most similar chunks by cosine distance are returned. This grounds the language model in external information.
Similarity is not semantic equivalence. An analyst asking about “customer revenue” may retrieve documents about customer billing entities, shipping accounts, parent relationships or gross versus net revenue. Enterprise analytical questions typically require computation, not just retrieval: computing Q3 contribution margin in a region depends on a specific formula, a fiscal calendar, a region schema and a data source. RAG is a legitimate component of modern agents, but its accuracy plateaus in the low‑ to mid‑70s and it cannot by itself resolve ambiguous terms or execute deterministic computations.
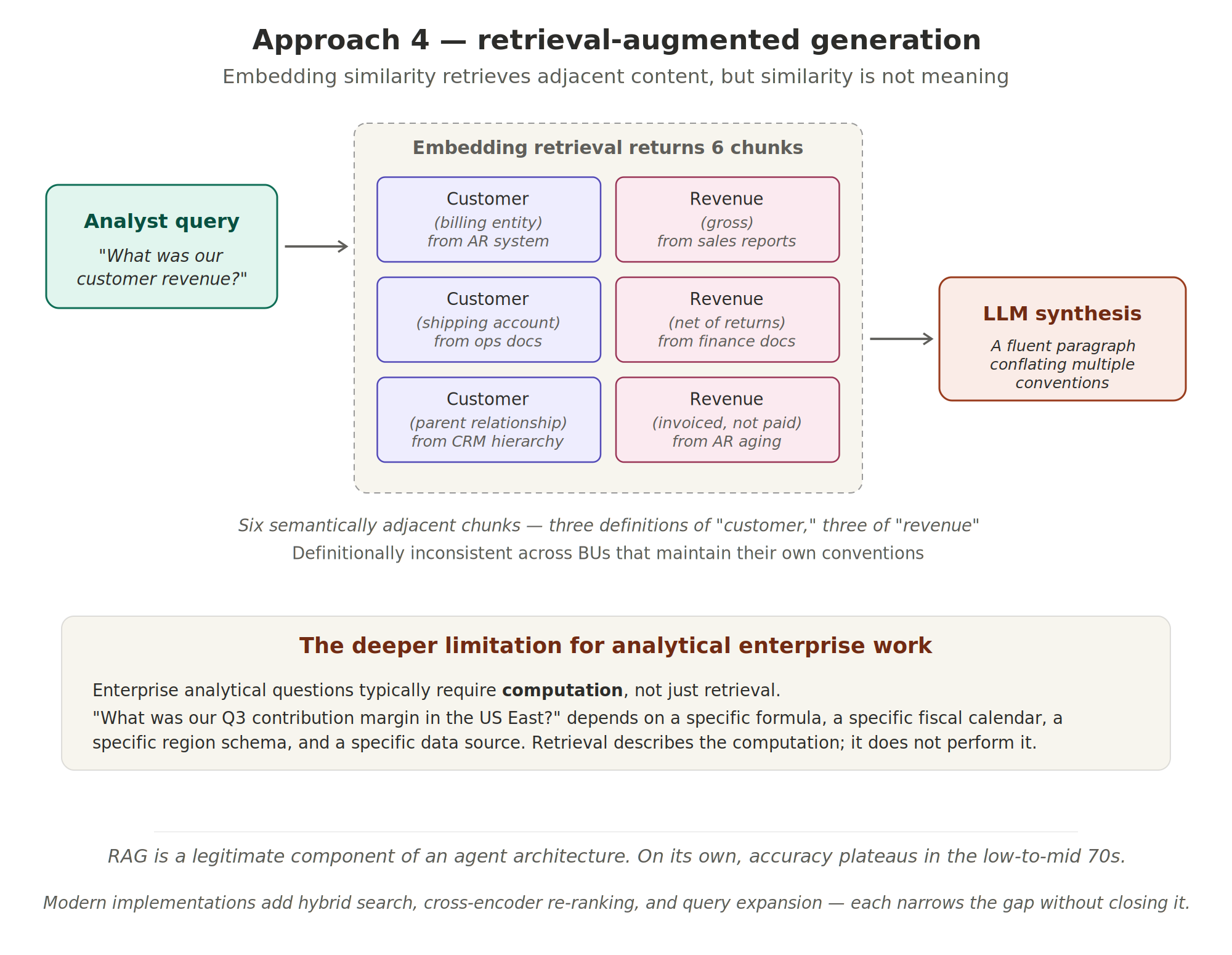
Figure 5. Approach 4—retrieval‑augmented generation. Embedding similarity retrieves semantically adjacent content, but similarity is not meaning. Enterprise analytical questions typically require computation rather than document lookup; retrieved chunks may conflate multiple conventions and accuracy plateaus accordingly.
3. The architectural complement — the value framework
Each of the four approaches above delivers genuine capability: long‑context prompting brings volume, LoRA enables parameter‑efficient adaptation, caching relieves compute cost and retrieval grounds the model in external data. None, however, meets the full bar for enterprise reliability and auditability. We believe the solution is an architectural complement rather than a replacement: externalizing knowledge into a persistent value framework that sits alongside the model.
The value framework is a structured knowledge layer containing canonical business definitions, rules, reference tables and validation constraints. Every agent resolves business terms here before the language model sees anything. Concepts such as contribution margin, Enterprise Customer, customs entry and other domain items map to versioned definitions maintained by subject‑matter experts. Because the framework is external, items can be edited, versioned and audited without retraining; changes are reviewed and verified automatically for consistency and invariants.
At inference time the analyst’s question arrives at the resolution layer first. Business terms are resolved to their canonical definitions; the relevant data is fetched from the appropriate sources; the necessary computations are executed deterministically outside the language model. The model’s role becomes narrow and purposeful: it receives a compact prompt describing the resolved question, performs reasoning and code generation over that context and produces a natural‑language answer. The execution and validation layer runs the generated code in a sandbox, executes automated evaluations and returns traceable outputs.

Figure 6. The value framework as an architectural complement. The analyst’s question arrives at the resolution layer first; business terms are resolved to canonical definitions, data is fetched and computations are executed outside the LLM. The probabilistic layer has a narrow role: it generates code and natural language over resolved context. Execution and validation run after the LLM, making every answer traceable to specific framework items.
4. Where this leaves us
The approaches in Section 2 are not wrong. Each delivers a genuine improvement over what came before it, and each has its appropriate use. Long-context prompting is useful for bounded contexts where the signal density is already high. LoRA is appropriate for stylistic and capability adaptation that does not change on the business-cadence timescale. Prompt caching is a sensible optimization for stable long prefixes. Retrieval is a legitimate component of any agent that grounds against a documentation estate. What none of them achieve on their own is the architectural property enterprise deployments actually require: knowledge that is explicit, versioned, authored, auditable, and updatable at the cadence the business itself moves.
The value framework is not a replacement for these techniques. It is the architectural complement that makes them work together. Retrieval becomes more precise when the framework resolves ambiguous terms before the retrieval runs. Long context becomes effective when the framework compresses the business knowledge into a short signal-dense prompt. Caching becomes safer when the framework manages semantic invalidation at the item level. Fine-tuning becomes optional when the knowledge no longer has to be encoded into the weights. The model's native capability — reasoning, composition, language — is directed at the work it does best, and the knowledge that must be defensible sits in a layer the company can see.
In the third installment of this post we show what perceptive agents look like when the value framework is deployed against real customer workloads — including the operational disciplines that produce production-grade reliability, the flywheel that makes each subsequent deployment stronger than the last, and the specific architectural choices that turn this from a research thesis into a shipping product.
References
[1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. arXiv preprint arXiv:1706.03762.
[2] Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2024). Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics.
[3] Hu, E. J., Shen, Y., Wallis, P., Allen‑Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021). LoRA: Low‑Rank Adaptation of Large Language Models. arXiv preprint arXiv:2106.09685.
[4] Dao, T., Fu, D. Y., Ermon, S., Rudra, A., & Ré, C. (2022). FlashAttention: Fast and Memory‑Efficient Exact Attention with IO‑Awareness. arXiv preprint arXiv:2205.14135.
[5] OpenAI. Prompt caching. OpenAI Platform Documentation.
[6] Anthropic. Prompt caching. Anthropic API Documentation.
[7] E. Lumer, F. Nizar, A. Jangiti, K. Frank, A. Gulati, M. Phadate, and V. K. Subbiah, “Don’t Break the Cache: An Evaluation of Prompt Caching for Long-Horizon Agentic Tasks,” arXiv:2601.06007, January 2026.
[8] Y. Du, M. Tian, S. Ronanki, S. Rongali, S. Bodapati, A. Galstyan, A. Wells, R. Schwartz, E. A. Huerta, and H. Peng, “Context Length Alone Hurts LLM Performance Despite Perfect Retrieval,” arXiv:2510.05381, October 2025.
[9] Anthropic, "Introducing Contextual Retrieval," September 2024. https://www.anthropic.com/news/contextual-retrieval