From “Task”ative Agents to Perceptive Agents
Part 1 of the Pedestal AI Knowledge Series · by Prem Ranga
Abstract
Enterprise AI has a stubborn ceiling. Frontier models now handle general tasks with astonishing fluency, yet the agents built on top of them keep stalling at 70–80% accuracy on the operational work that actually runs a business. This is not a model problem; it is a knowledge problem — and specifically a problem of where knowledge lives. This post opens a three-part examination of the gap, beginning with the problem itself. We describe what we call “Task”ative agents and the shift toward perceptive agents that the field now needs, and walk through five common challenges we have observed across dozens of structured conversations with customers across industries. At Pedestal we believe the solution lies in an architectural complement - externalizing knowledge into a value framework that sits alongside the model and supplies the perception it cannot provide on its own. The second and third installments of this post develop that approach in detail: how the value framework is structured, and what perceptive agents look like deployed against real enterprise workloads.
1. The decade of the gap
The word that is missing from most conversations about enterprise AI is perception. Not as a loose synonym for awareness, but in its precise sense: the ability to take in a situation, recognize what it means in a specific context, and act with understanding of the consequences. When a senior customs broker glances at a shipment manifest and immediately flags the Section 301 exposure on line 7, the HTS misclassification risk on line 11, and the FDA hold that will push release past the Friday vessel cutoff — that is perception. When a junior clerk files the same manifest cleanly but unaware of any of it, that is execution without perception. Both complete the task. Only one is reliable.
Most enterprise AI agents today are junior analysts. They are what we at Pedestal have come to call Taskative agents: fluent, confident, task-completing — and structurally unable to recognize when they are wrong. They run pipelines (question → similarity search → enriched context → reasoning → function call → answer) that look reasonable from the outside and execute correctly on most inputs. They fall short in the ways that matter most: silently, on the edge cases where domain knowledge was supposed to catch them, and with no way for an operator to tell the difference between a good answer and a plausible-sounding one that happens not to be.
We have been thinking about this problem for a long time. Members of our team have tracked the evolution of transformer architectures since the late 2010s — from the original attention paper through BERT, GPT-2, T5, and into the frontier models of the 2020s. We have watched, and in many cases contributed to, a decade of model growth: from millions to billions to now trillions of parameters; from narrow task-specific fine-tuning to zero-shot generalization; from the surprise that scale worked at all to the current era where frontier intelligence is a given. What has not changed across that entire arc is the gap between raw model capability and reliable enterprise behavior. Every successive leap in parameters and capability has shifted the ceiling up, but the gap itself has stayed roughly the same size. The model gets smarter; the enterprise still cannot trust it with the thing that matters. That stability of the gap, across ten years and four orders of magnitude of scale, is what convinced us the problem was not going to be solved by waiting for the next model release. It needed a different kind of work.
The paradigm shift we refer to is the move from agents that execute tasks to agents that are situationally aware. A perceptive agent still runs the same pipeline, but every stage is now guided by an explicit layer of knowledge — intent, domain definitions, data references, business rules, validation constraints, and derived meaning. The pipeline does not get longer. The ground underneath it gets firmer.
There is a useful analogy in Stephen Covey's framework from The 7 Habits of Highly Effective People: the distinction between what we do and the values that guide how we do it. A Tas(l)kative agent is pure doing — competent at the motion, agnostic about the meaning. A perceptive agent operates against a value framework: a cognizance layer of what things mean in this specific business, what rules apply, what outcomes matter. The framework does not slow the agent down; it is what lets the agent move without drifting. Everything that follows in this three-part post is, in one way or another, about how to build that cognizance layer for an AI system — and why it works when pure scaling does not.
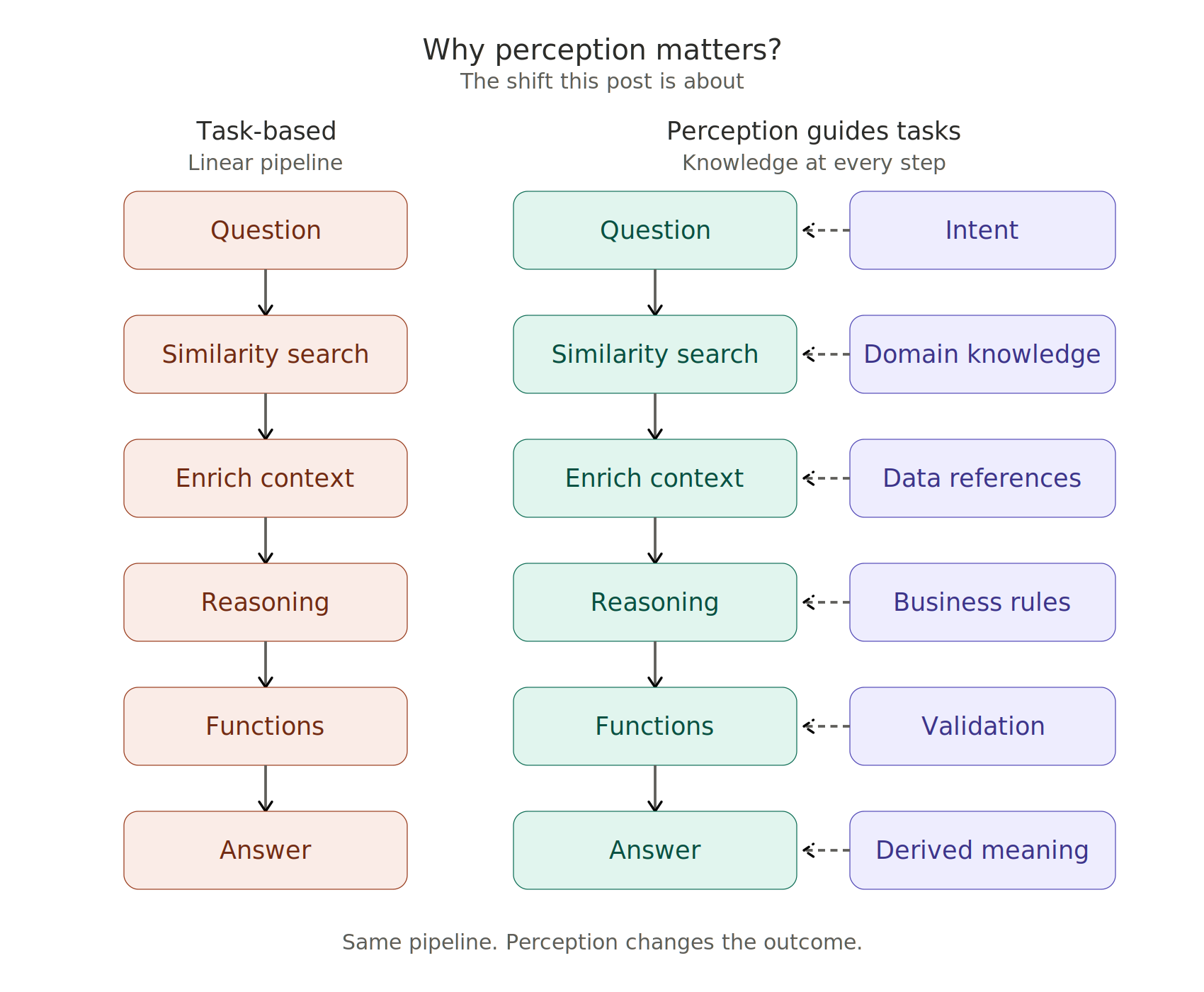
Figure 1. Same pipeline, different outcomes. On the left, a task-based agent runs a linear chain of steps without any grounding in business meaning. On the right, each step is guided by an explicit layer of perception — intent, domain knowledge, data references, business rules, validation, derived meaning — that sits alongside the pipeline and supplies the context the model alone cannot provide.
2. Common challenges with enterprise AI
Before describing the architecture that closes the gap, it is worth being precise about what the gap actually looks like on the ground. Over the past eighteen months we have had structured conversations with dozens of enterprise teams — in logistics, automotive, manufacturing, retail, financial services, and shipping — about their AI deployments. The same five observations recur in almost every conversation. They are not independent; they are different angles on the same underlying situation, which is that knowledge does not have a dedicated architectural home. But each one shapes how enterprise teams experience the ceiling in its own way, and naming them separately helps clarify what needs to change.
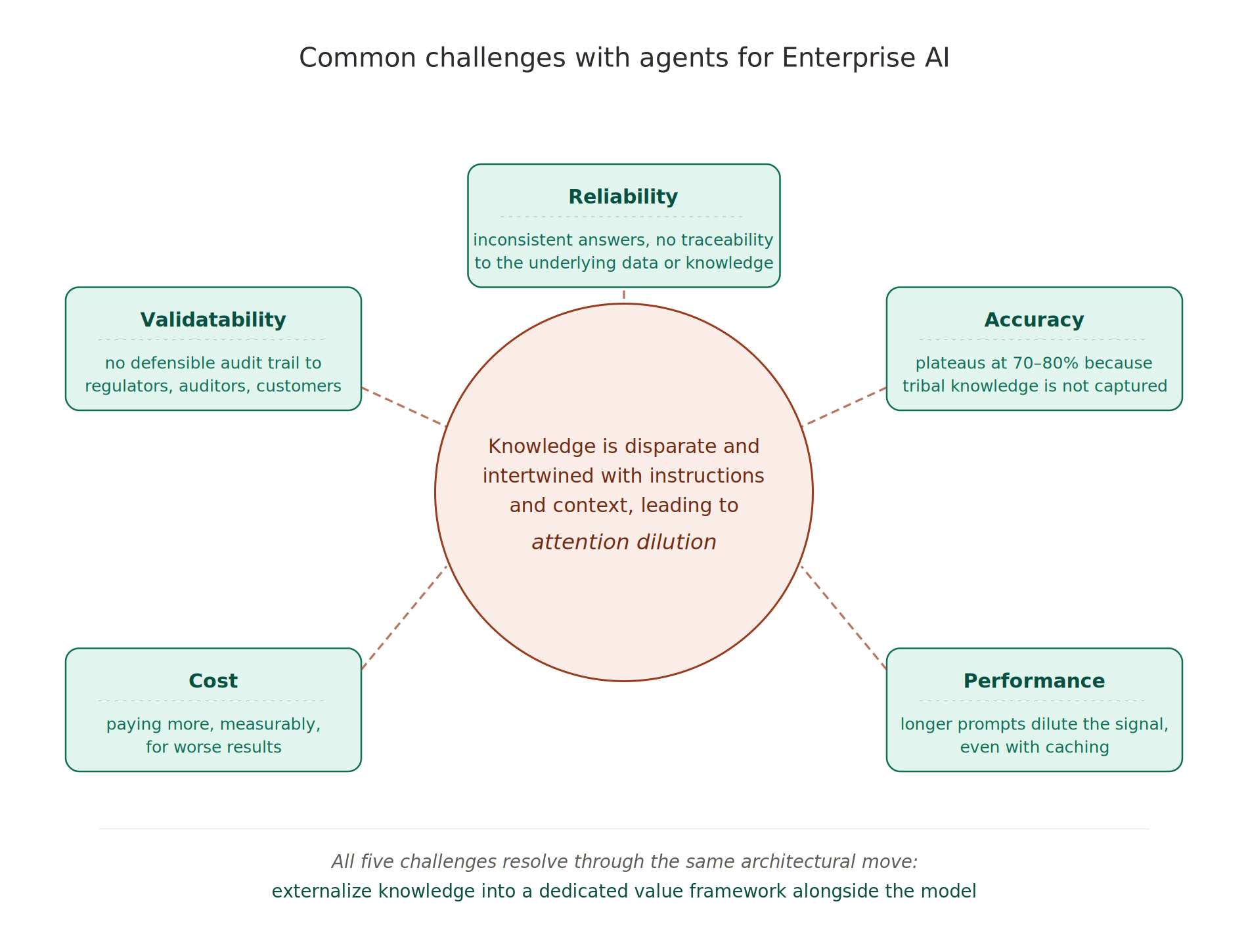
Figure 2. Five common challenges with agents for Enterprise AI, shown as segments around a central core. Each challenge looks different on the surface — reliability, accuracy, performance, cost, and “validat”ability — but all five share a single architectural origin: knowledge is disparate and intertwined with instructions and context, leading to attention dilution. The remainder of this post and the two installments that follow develop the architectural fix: externalize knowledge into a dedicated value framework alongside the model.
2.1 Reliability — an epistemological situation, not a QA situation
Reliability in enterprise AI is not a quality-assurance issue. It is an epistemological one. Teams do not stall because their agents are buggy; they stall because nobody can tell, on a given answer, whether the system got it right. This is compounded by the consistency problem - due to the probabilistic nature of the underlying models, unless specifically addressed, the agent may generate answers that look similar but are actually different when analyzed in detail. A logistics agent that generates a customs entry cannot be audited by reading its output — the output is indistinguishable, at the level of text, from an entry produced by a human broker with twenty years of experience and an entry produced by a fluent generator with no understanding of the underlying regulations. The only way to know is to trace the answer back to the specific rules, definitions, and data sources that produced it. Most agent architectures make that trace impossible. The knowledge that drove the answer is distributed diffusely across billions of model weights, and no amount of logging retrieves it.
Reliability also has a temporal dimension we will return to in Part 2 of this series: even a system that produces a correct answer today may silently drift as the organization underneath it evolves. The architecture that delivers reliability must address both the audit-trail problem and the stability-over-time problem, and they turn out to have the same solution.
2.2 Accuracy — fluency is not correctness
Accuracy is the surface symptom. Enterprise teams routinely report getting to 70–80% accuracy on a target workload, then plateauing there for months. The last 15–25 points are not a scaling problem; they are tribal knowledge — the exceptions, conventions, and half-documented rules that a senior employee holds in their head and that never made it into any training corpus or retrieval index. A finance analyst knows that margin for this business unit excludes a specific freight-recovery line because of a 2022 reorg. A customs broker knows that certain shell entries tagged '595' should be excluded from the duty calculation. A sales ops lead knows that 'Enterprise Customer' means revenue above a threshold and a named-account status and a signed MSA — not just the first of those. An agent that misses any of these produces an answer that is reliably inaccurate in exactly the way a novice is reliably inaccurate: fluent, formatted correctly, and off by enough to matter.
2.3 Performance — the hidden latency tax
Performance degrades in a specific and measurable way as teams attempt to compensate for missing knowledge by stuffing more into the prompt. The intuition is reasonable: if the agent doesn't know what margin means, include the definition in the prompt. If it doesn't know the fiscal calendar, include that too. And the rules. And a few examples. And the schema. Prompts that start at 2K tokens swell to 8K, then 32K, then 128K — and at each step, the 'prefill' latency grows quadratically with context length while the effective signal density falls. Agents that answered in 3 seconds at 4K tokens take 18 seconds at 48K, and the answer quality has degraded along the way because the critical definition is now one of thirty thousand tokens competing for attention.
Modern caching infrastructure has partially addressed the compute side of this situation. Once a long prefix is cached by the model provider, the prefill cost is amortized across subsequent queries and the raw latency penalty softens. What caching does not address is the deeper mechanism underneath: attention mass is finite, and spreading it across forty thousand tokens dilutes the critical signal regardless of whether the computation is cached or fresh. Nor does caching know when a cached business rule has been superseded — semantic invalidation remains on the enterprise team even when the compute ledger is handled for them by model providers.
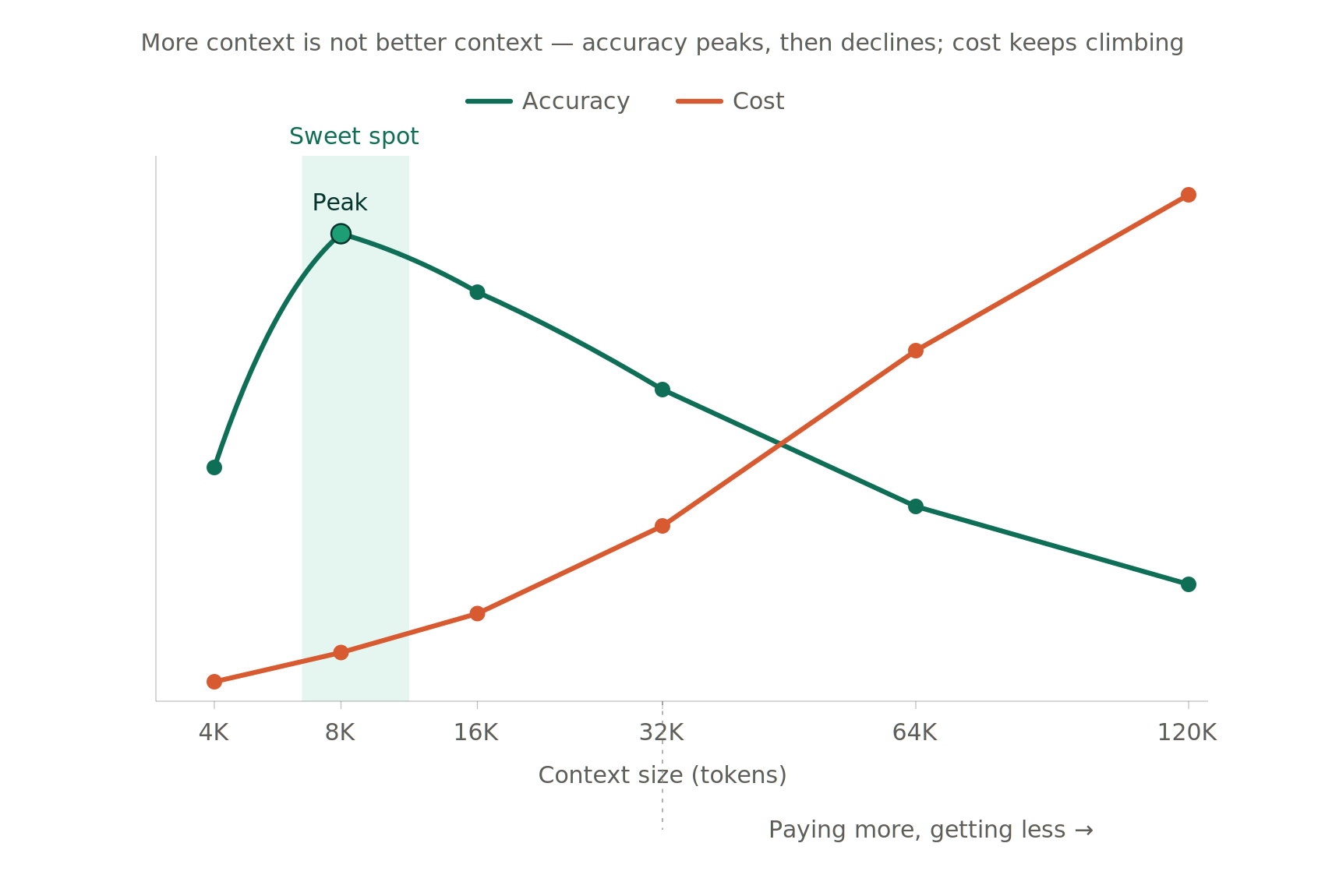
Figure 3. The Goldilocks zone. Accuracy peaks at a narrow context window between 8K and 12K tokens and declines beyond that; cost climbs monotonically with context size. Agents that operate above 16K as the normal case are paying more for worse results, measurably.
2.4 Cost — paying more, measurably, for inadequate results
Cost follows directly from the same mechanism but lands on a different budget line. We have measured this carefully across real customer workloads. Going from a 4K-token prompt to a 32K-token prompt on the same question typically produces: 4× the per-query dollar cost, 3× the latency, and — crucially — an accuracy drop of roughly 4 percentage points, because the critical business rule now competes with thirty thousand other tokens for attention mass. The inference cost might be reported as a single line; what it does not report is that the team is paying that cost to get answers that are inadequate than what a smaller, more targeted prompt would have produced.
Caching shifts these economics for stable long contexts by reducing the per-query compute on prefix tokens, which the second installment of this post examines in detail. What caching cannot shift is the underlying dilution of signal under softmax attention. The real cost is not what teams pay per query; it is what they lose in answer quality.
2.5 "Validate"ability — the audit trail enterprise deployments require
This is the issue that quietly holds deployments back at the finish line. An agent might clear 85% accuracy on a test set and still not reach production, because nobody in the organization can state consistently that they would be comfortable defending any individual answer to a regulator, auditor, or customer. The agent is a black box, the retrieval is a black box, the reasoning is a black box, and when the inevitable inaccurate answer reaches a VP, there is no way to point at the specific rule or data point that produced it. Pilots that reach 85% accuracy frequently do not reach production, because 'good enough on average' is not a defensible position in a regulated industry, and most industries are at least partly regulated.
These five observations look different on the surface but they share a single architectural cause. In every case, the knowledge that was supposed to ground the answer is placed where it cannot be read, audited, or selectively updated — diffused through model weights, buried in prompt text, embedded in undocumented dashboard logic, or held in the head of a senior employee who has not yet been asked the right question. Give knowledge a dedicated architectural home — a place where it can be read, authored, versioned, and audited — and all five observations resolve through the same move.
Where this leaves us
These observations indicate a common cause; knowledge is not addressed as a specific pursuit. If the observations were describing genuinely independent phenomena — one a retrieval limitation, one a fine-tuning artifact, one a prompt engineering constraint — the path forward would be an open-ended search across five separate problem spaces. But they are not independent.
Our research and operational experience at Pedestal point consistently to a single architectural move that addresses all five observations at once. When knowledge is externalized — authored as structured items bound to specific data sources, versioned, traceable, and referenced explicitly at inference rather than intertwined in through the prompt or compressed into the weights — each of the patterns these teams have observed resolves together rather than separately. We call the structured form of this externalized knowledge a value framework: a persistent layer of domain definitions, metrics, rules, and validation constraints that sits alongside the model and supplies the perception the model alone cannot provide. The value framework is what makes an agent perceptive in the sense Section 1 described. It is not retrieval-augmented generation, though retrieval is one component of it. It is not fine-tuning, though the underlying model can be fine-tuned in parallel. It is a distinct architectural surface with its own properties: explicit, versioned, human-authored, machine-readable, and designed to compound across deployments.
In the second installment of this post we will dive deep into the specifics of the value framework. We will walk through the decoder-only transformer architecture at the level of attention mathematics, examine the four most common remedies enterprises have tried — long-context prompts, LoRA based fine-tuning, prompt caching, and retrieval-augmented generation — and discuss how the premise of knowledge encoded using these approaches are insufficient to achieve enterprise reliability. We then introduce the value framework in operational detail, showing how each of its components maps back to an observation from our experiments. In the third part of this post we will show what perceptive agents look like when the value framework is deployed against real customer workloads, along with the disciplines that produce production-grade reliability, and the flywheel that makes each subsequent deployment stronger than the last.
In a nutshell; reliable enterprise adoption is achieved by perceptive agents that instill a value framework in how they operate and this requires a solution that can leverage implicit human knowledge.